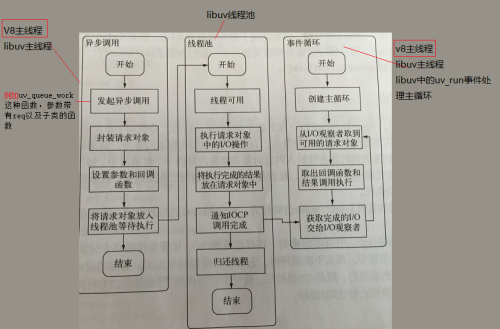
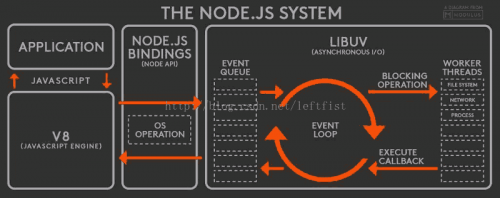
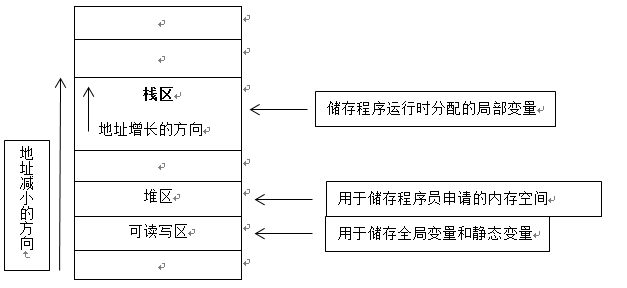
转载自:https://www.cnblogs.com/mrxiaohe/p/5072034.html
1. 什么是JavaScript解析引擎?
简单地说,JavaScript解析引擎就是能够“读懂”JavaScript代码,并准确地给出代码运行结果的一段程序。比方说,当你写了 var a = 1 + 1; 这样一段代码,JavaScript引擎做的事情就是看懂(解析)你这段代码,并且将a的值变为2。
学过编译原理的人都知道,对于静态语言来说(如Java、C++、C),处理上述这些事情的叫编译器(Compiler),相应地对于JavaScript这样的动态语言则叫解释器(Interpreter)。这两者的区别用一句话来概括就是:编译器是将源代码编译为另外一种代码(比如机器码,或者字节码),而解释器是直接解析并将代码运行结果输出。 比方说,firebug的console就是一个JavaScript的解释器。
但是,现在很难去界定说,JavaScript引擎它到底算是个解释器还是个编译器,因为,比如像V8(Chrome的JS引擎),它其实为了提高JS的运行性能,在运行之前会先将JS编译为本地的机器码(native machine code),然后再去执行机器码(这样速度就快很多),相信大家对JIT(Just In Time Compilation)一定不陌生吧。
我个人认为,不需要过分去强调JavaScript解析引擎到底是什么,了解它究竟做了什么事情我个人认为就可以了。对于编译器或者解释器究竟是如何看懂代码的,翻出大学编译课的教材就可以了。
这里还要强调的就是,JavaScript引擎本身也是程序,代码编写而成。比如V8就是用C/C++写的。
2. JavaScript解析引擎与ECMAScript是什么关系?
JavaScript引擎是一段程序,我们写的JavaScript代码也是程序,如何让程序去读懂程序呢?这就需要定义规则。比如,之前提到的var a = 1 + 1;,它表示:
- 左边var代表了这是申明(declaration),它申明了a这个变量
- 右边的+表示要将1和1做加法
- 中间的等号表示了这是个赋值语句
- 最后的分号表示这句语句结束了
上述这些就是规则,有了它就等于有了衡量的标准,JavaScript引擎就可以根据这个标准去解析JavaScript代码了。那么这里的ECMAScript就是定义了这些规则。其中ECMAScript 262这份文档,就是对JavaScript这门语言定义了一整套完整的标准。其中包括:
- var,if,else,break,continue等是JavaScript的关键词
- abstract,int,long等是JavaScript保留词
- 怎么样算是数字、怎么样算是字符串等等
- 定义了操作符(+,-,>,<等)
- 定义了JavaScript的语法
- 定义了对表达式,语句等标准的处理算法,比如遇到==该如何处理
- ⋯⋯
注:js兼容性问题的原因
标准的JavaScript引擎就会根据这套文档去实现,注意这里强调了标准,因为也有不按照标准来实现的,比如IE的JS引擎。这也是为什么JavaScript会有兼容性的问题。至于为什么IE的JS引擎不按照标准来实现,就要说到浏览器大战了,这里就不赘述了,自行Google之。
所以,简单的说,ECMAScript定义了语言的标准,JavaScript引擎根据它来实现,这就是两者的关系。
3. JavaScript解析引擎与浏览器又是什么关系?
简单地说,JavaScript引擎是浏览器的组成部分之一。因为浏览器还要做很多别的事情,比如解析页面、渲染页面、Cookie管理、历史记录等等。那么,既然是组成部分,因此一般情况下JavaScript引擎都是浏览器开发商自行开发的。比如:IE9的Chakra、Firefox的TraceMonkey、Chrome的V8等等。
从而也看出,不同浏览器都采用了不同的JavaScript引擎。因此,我们只能说要深入了解哪个JavaScript引擎。